

In the context of machine learning, the concept of transfer learning is simple. Transfer learning means taking a model that’s been trained on a task and using what it’s learned to jumpstart performance on another, different, but related task. Basically, it means that machines can acquire knowledge and apply it on related tasks.
While the concept seems simple it still has significant applications for machine translations, healthcare and diagnostics, automotive industry, recruitment AI, and more.
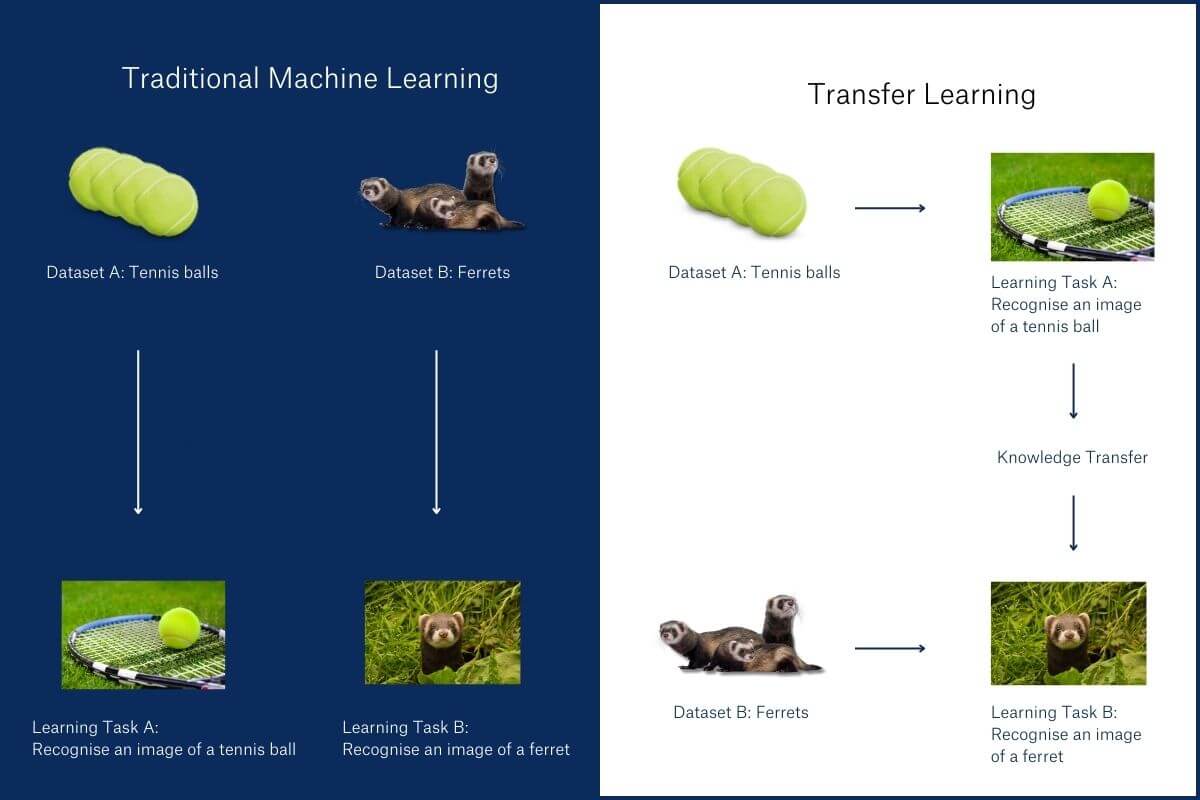
How Does Transfer Learning Work?
Transfer learning works like this:
- First, we take a model trained to identify an image. Let’s say – an image of a tennis ball.
- Second, we use what that model learned and train it on a new task – for example, to identify whether an image contains a ferret.
This might seem a curious example. After all, what do tennis balls and ferrets visually have in common? Why would learning to recognise the first help to recognise the second?
A model that’s learned to reliably identify tennis balls has learned much about contours, textures, shapes, shadows, and more. That makes this ball-trained model a far better starting point than a model that has never dealt with features necessary to identify an image.
When it comes to identifying ferrets, this trained model will tap into its learned ability to process pixels into conceptual shapes. In fact, a typical multilayered model in use today has only a tiny proportion of its stored knowledge that’s truly task-specific: the rest is the foundation that makes the task possible.
What Makes Transfer Learning Useful for Machine Learning?
There are two major factors that make transfer learning an important element of machine learning.
Time saving - If the knowledge that a model acquired can be applied to a new task, it means that it doesn’t have to be trained from scratch. This saves time and resources.
Solving tasks with scarce data available – Sometimes, even if we have the time to train the model from scratch, there simply isn’t enough data available for such an endeavour. In these situations, transfer learning from another model is not just convenient, but necessary. This may well be true of our example of learning to identify ferrets: they are far less numerous than tennis balls in the world, and in any case secretive and hard to spot.
Using Transfer Learning vs Treating Tasks as Unrelated
Why not simply treat these as unrelated tasks and handle them separately?
The answer is that learning to recognise anything moderately complex from a clean slate is incredibly difficult. It can require daunting amounts of time and data for a machine. We humans have no personal experience of starting from a slate so clean. Our visual system is produced from millions of years of evolution (plus a small amount of ontogeny).
Therefore, the raw sensory input entering our eyes when we look a tennis ball is so thoroughly processed, abstracted, and “chunked” by this visual system into contours, textures, shapes, and shadows, that even if we have never seen a tennis ball before, our task of learning to recognise one is already almost done for us.
We perceive an object with attributes we already understand. We notice features such as roundness, fuzziness, yellowness, size. That’s why we typically only need to be shown one or two examples before we can confidently point out never-before-seen tennis balls to our friends with almost perfect accuracy.
A machine has no such advantage: they truly can, and often must, learn from scratch. This is often termed “random weight initialisation.”
How Is Transfer Learning Applied in a Model?
What a neural network model has learned is embedded in binary representations of real-valued numbers. Collectively, these are known as its weights, or parameters.1 In fact, a model is nothing other than these weights, and a defined series of arithmetical operations that use them to transform inputs into outputs. Training, similarly, is nothing other than optimising the values of these weights.
Transfer learning, then, can be as simple as this:
- Pre-training: Randomly initialise a model, and then train on a dataset of (input, expected_output) samples representing task A.
- Fine tuning: Keep the weights learned from task A, switch the dataset to (input, expected_output) samples representing task B, and train again.
At the beginning of step 2, the model will still be performing task A, and therefore not performing task B (except by coincidence). Still, it will hopefully be close in weight space to a model that can perform task B. The “fine tuning” step will then be relatively fast, and low in data requirements.
Types of Transfer Learning
We can add nuance and complexity to the transfer learning procedure in a few ways:
- If the new task has a different output format (e.g. if we are changing from a binary classification task to a categorical classification task), then we’ll typically replace the old final layer with a new one of the necessary shape, randomly initialised, while keeping the rest of the weights intact.
- If we want the model to not forget important elements of the original task, we may constrain its weights during the fine-tuning phase so that they remain close to their original values.
- We may add multiple output layers to our model and train it on different tasks simultaneously.
Taking things a bit further:
- Transfer learning can be bidirectional: as we gather more training data, knowledge from task A may feed into task B, and then back again.
- Transfer learning can also be iterated. After transferring knowledge from task, A to task B, we can do the same from task B to task C, where even fewer examples may exist.
- A less obvious example of transfer learning can be found in models where training data evolves over time. For example, when new document formats enter our existing dataset, the task of the model changes, even if only slightly, and it must transfer what it has learned from the previous data distribution to a new one.
An Example of Transfer Learning: Affinda AI
Affinda specialises in training and using AI models to understand documents. The document types we support include resumes, invoices, identity documents, and others. These require specific, fine-tuned language models. This is true for both out-of-the-box and custom-developed solutions.
However, acquiring the volume of annotated document examples required training models from scratch is usually cost-prohibitive, and sometimes impossible.
Transfer learning eliminates the necessity to start from scratch with every problem. For our models, it’s implemented with a pre-training routine that involves learning from millions (sometimes billions) of documents. The task here is simple: we mask a word from the model’s view and ask the model to predict the masked word. Like identifying tennis balls, this may not seem a practically useful task, since words in actual documents rarely go missing and need to be replaced.
However, it forces an immense body of foundational knowledge to be learnt first – syntax, semantics, grammar, layout, structure – in order that the masked words can be reconstructed.
Once this knowledge is in place, we can learn other, useful tasks – like finding and parsing a field of interest from a document, regardless of its format or location, using relatively few training examples.
In practical terms, this means we don’t need to annotate nearly as many documents as we would, if we were trying to do without transfer learning and teach our model from scratch.
Furthermore, our models can learn online, evolving their weights to cater for new documents without forgetting how to interpret old ones, and they can also learn from partial examples. If we have fields which are only annotated in subsets of our training data, we can recognise this and learn tasks from documents selectively.
Transfer learning makes possible a document automation platform that evolves constantly with every task and document it processes. If you’d like to harness that power and apply it to your own business’s needs, make sure to contact us and discuss it with our team. We will find the best document processing AI solution for you, whether that is an off-the-shelf or a custom solution.


